理解 Rust 异步编程是一个自下而上的过程,其核心基石在于对 IO 模型 的理解。只有掌握了 IO 模型,才能明白异步编程模型是如何在其基础上构建并运作的。
以下是基于提供的源码对 IO 核心概念及模型的详细解析:
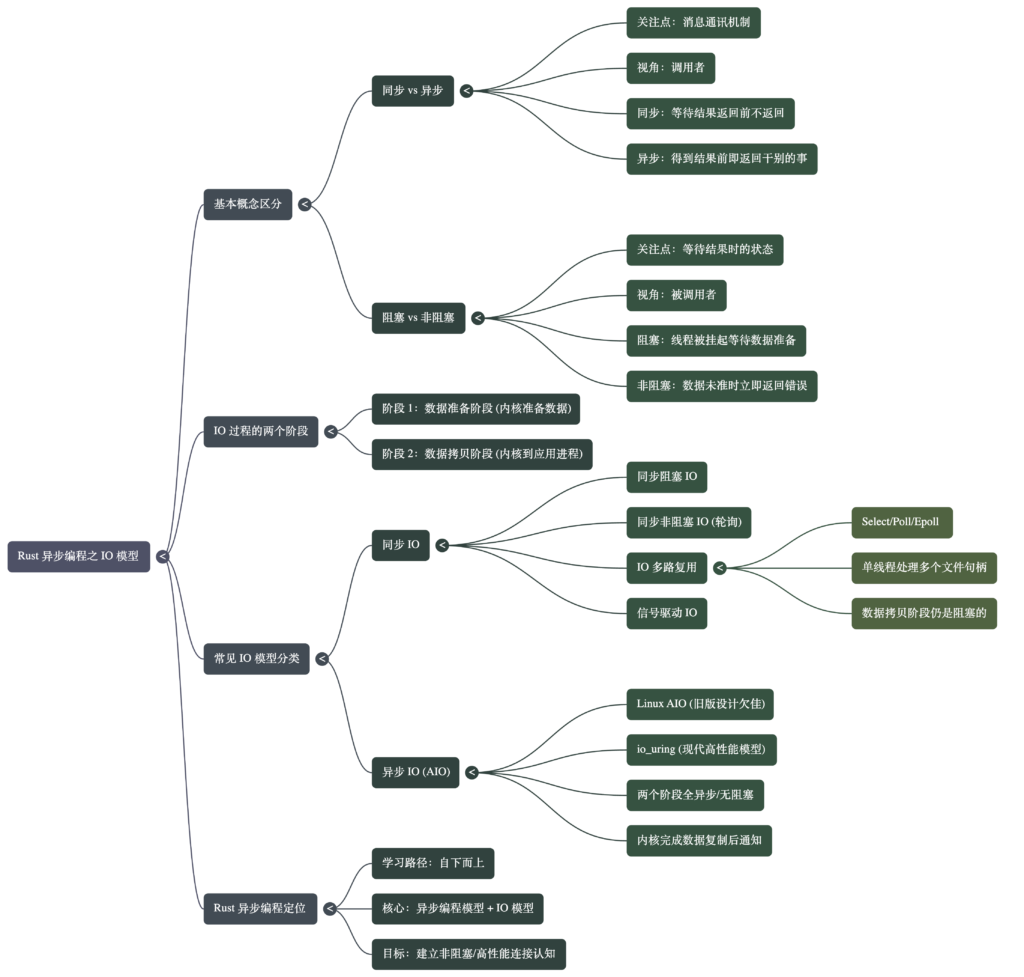
1. 核心概念辨析
在讨论 IO 时,经常会混淆同步/异步与阻塞/非阻塞,它们关注的视角各不相同:
- 同步 vs 异步 (Synchronous vs Asynchronous):
- 视角:站在调用者的角度。
- 同步:调用者发起请求后,在没有得到结果之前不返回,一直等待。
- 异步:调用者发起请求后,在没有得到结果之前就立即返回,转而执行其他任务。其关注点在于任务何时完成,通常通过通知机制来实现。
- 阻塞 vs 非阻塞 (Blocking vs Non-blocking):
- 视角:站在被调用者(如内核)的角度,关注程序等待结果时的状态。
- 阻塞:在调用结果返回前,当前线程会被挂起,一直等待数据准备好。
- 非阻塞:在调用结果返回前,线程不会被挂起。如果数据未准备好,内核会立即返回一个错误(如
EWOULDBLOCK),允许线程处理其他逻辑。
2. IO 操作的两个阶段
任何数据输入(Input)操作实际上都包含两个阶段:
- 数据准备阶段:数据从硬件(如网卡)接收并到达内核空间。
- 数据拷贝阶段:将数据从内核缓冲区拷贝到用户态(应用程序)的进程空间中,。
关键区别:在所有的同步 IO 模型中,第二阶段(数据拷贝)永远是阻塞的。只有在真正的异步 IO 模型(如 Linux 的 io_uring)中,这两个阶段才都可以交给内核完成,用户进程无需参与阻塞拷贝过程,。
3. 通用 IO 模型分类
根据上述阶段的处理方式,IO 模型可分为两大类:
同步 IO 模型 (Synchronous IO)
- 同步阻塞 IO:两个阶段均处于阻塞状态。
- 同步非阻塞 IO:在数据准备阶段通过不断轮询(Polling)来检查状态,但在数据准备好后的拷贝阶段仍需阻塞等待。
- IO 多路复用 (IO Multiplexing):如 Linux 中的
epoll。它允许一个线程同时监控多个文件描述符。虽然它能显著提高性能,但在内核将数据拷贝到应用空间时,它依然属于同步模型,。
异步 IO 模型 (Asynchronous IO)
- 典型代表:Linux 的
io_uring(目前设计最优秀的模型)以及早期的AIO。 - 特点:整个过程(准备与拷贝)都由内核异步完成。调用后立即返回,直到内核通知数据已完全准备好并已放入用户空间,实现了真正的“零拷贝”感官体验或无阻塞状态,。
4. Rust 异步编程的语境
在 Rust 的语境下,我们通常讨论的是 “异步编程模型 + IO 模型” 的结合。
- 异步编程模型:指的是语言层面的
async/await编写方式。 - IO 模型:指的是底层操作系统提供的能力(如
epoll或io_uring)。 - 开发者需要区分这两者:即便编程模型是异步的,底层的 IO 模型可能是同步多路复用,也可能是真正的原生异步 IO。
比喻理解: 想象你在厨灶上煮开水:
- 同步阻塞:你站在水壶旁盯着,什么也不干,直到水开。
- 同步非阻塞:你去客厅看电视,但每隔一分钟就跑回厨房看看水开了没(轮询)。
- 异步:你给水壶装了一个汽笛(通知机制),然后直接去书房看书。你完全不用管厨房,直到汽笛声响(内核通知你数据拷贝完成),你直接过来提水即可。